上一篇 我们已经配置过zabbix的触发器了,也知道当触发器阀值达到时,应该有一个动作,而这个动作可以是执行脚本,也可以是发邮件报警通知用户。那么本篇我们将再进行对zabbix的报警进行配置。
报警媒介类型
当zabbix中的某些被监控指标出现异常时,zabbix会通过哪种方式通知运维人员呢?是通过邮件呢,还是通过短信呢,或者是通过其他方式呢?今天我们就来聊聊zabbix的报警方式,无论是通过邮件报警还是通过短信报警,无非都是通过某种”媒介”将报警信息传递给收信人,所以在zabbix中,报警方式被称为”报警媒介”,那么,zabbix都支持哪些报警媒介呢,我们一起来看看。
zabbix支持的报警媒介如下:
Email:邮件,这是最常用也是最传统的一种报警媒介,邮件报警,zabbix通过配置好的SMTP邮件服务器向用户发送对应的报警信息。Script:脚本,当zabbix中的某些监控项出现异常时,也可以调用自定义的脚本进行报警,脚本的使用就比较灵活,具体怎样报警全看你的脚本怎么写。SMS:短信,如果想要使用短信报警,则需要依赖短信网关(貌似需要北美的运行商)。Jabber:即时通讯服务。Ez Texting:商业的,收费的短信服务(北美运营商提供服务)。第三方的onealert
定义报警媒介
下面我们通过配置邮件报警媒介来进行配置说明
点击管理-报警媒介类型-创建媒介类型,输入完信息后,点击添加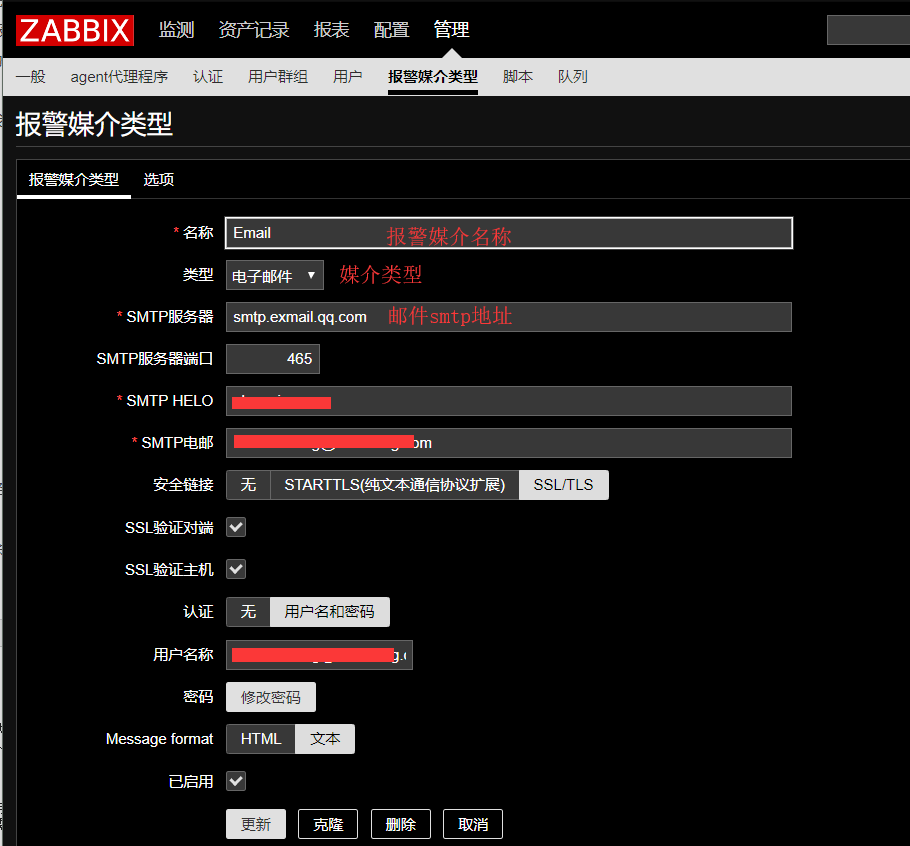
之后,我们可以在报警媒介类型中看到已经添加的报警类型,点击右边的测试,可以测试当前邮件配置是否正常,如果配置正常你将收到测试的邮件。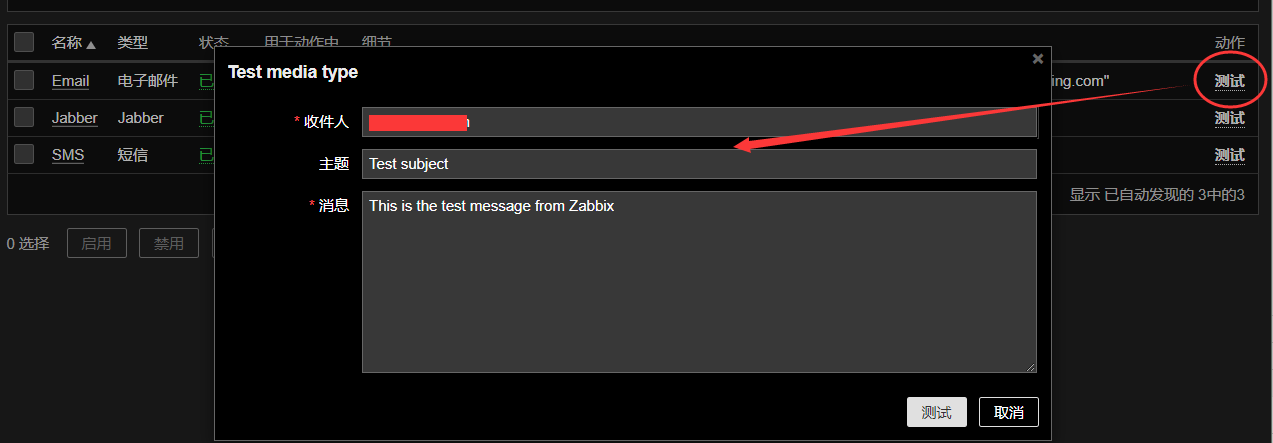
到此处,我们已经成功的定义了一个”报警媒介”,从此,我们可以通过这个媒介,向用户发送报警信息了。
配置用户接受报警通知媒介
但是,如果想要某个zabbix用户能够接收到从”email报警媒介”发送过来的报警,还需要进一步配置,比如,当”Admin”用户想要通过”email”报警媒介接收警报时,则必须能够”适配”这种媒介,如果”Admin”用户没有使用”email媒介”的能力,那么”Admin”用户将无法接收到由”email媒介”发出的报警信息。我们应该怎样让用户能够对应的报警媒介呢,配置步骤如下。
点击管理-用户-Admin-报警媒介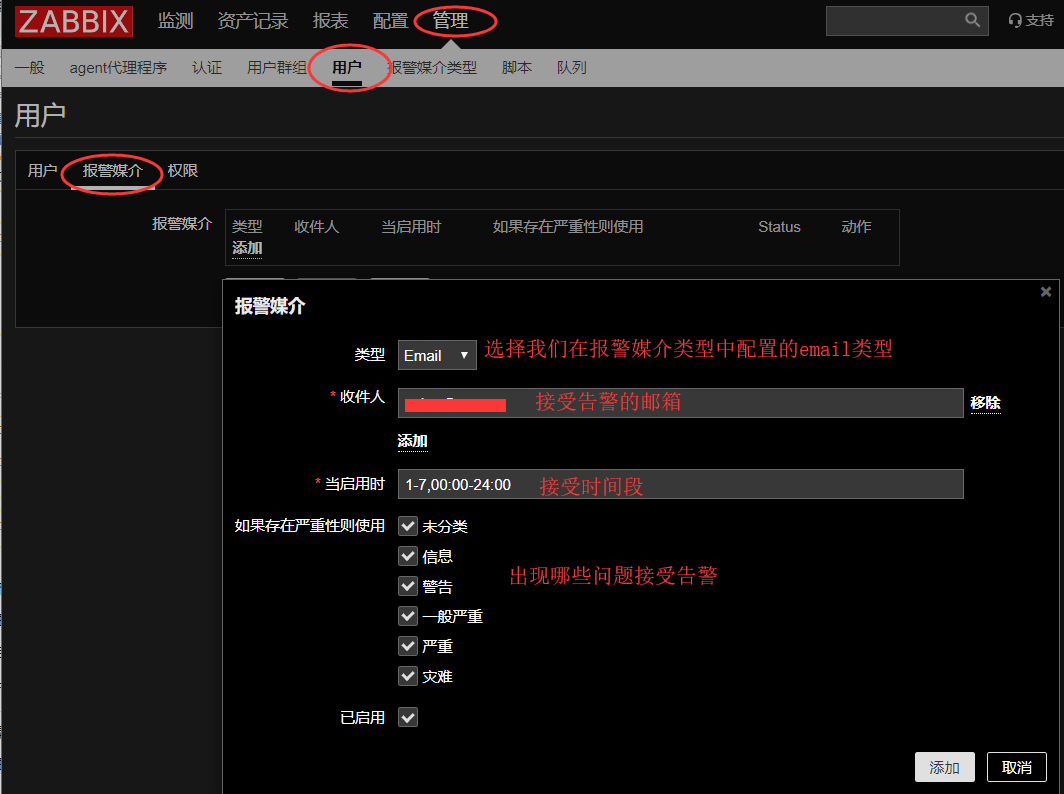
到此处,我们已经成功的定义了一个用户能接受对应”报警媒介”的邮件通知了。
配置告警动作
在zabbix中创建一个动作,前文中我们已经创建了用于监控磁盘根目录使用率的监控项,以及对应的触发器,现在,我们需要创建一个动作,与监控项和触发器结合起来一起使用。
打开zabbix控制台,点击配置-动作-事件源-触发器-创建动作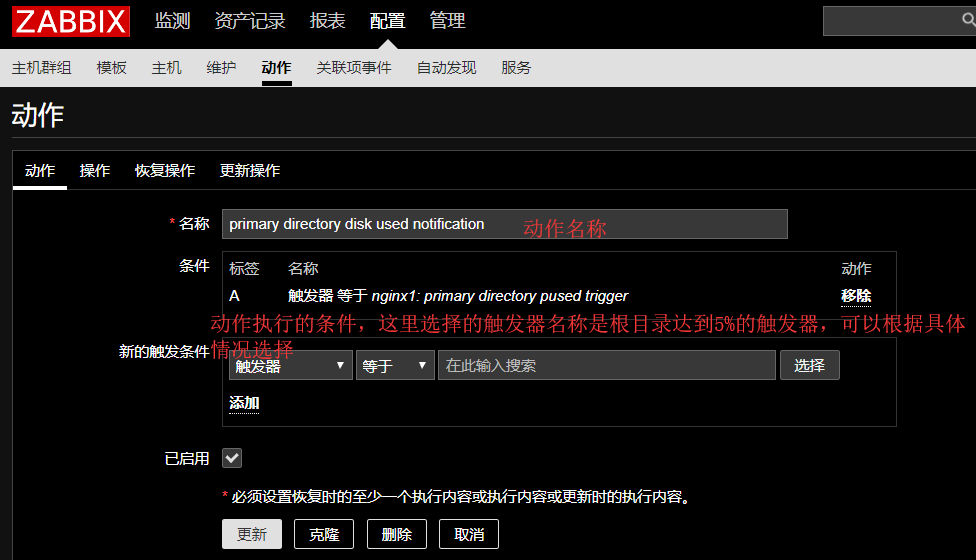
点击操作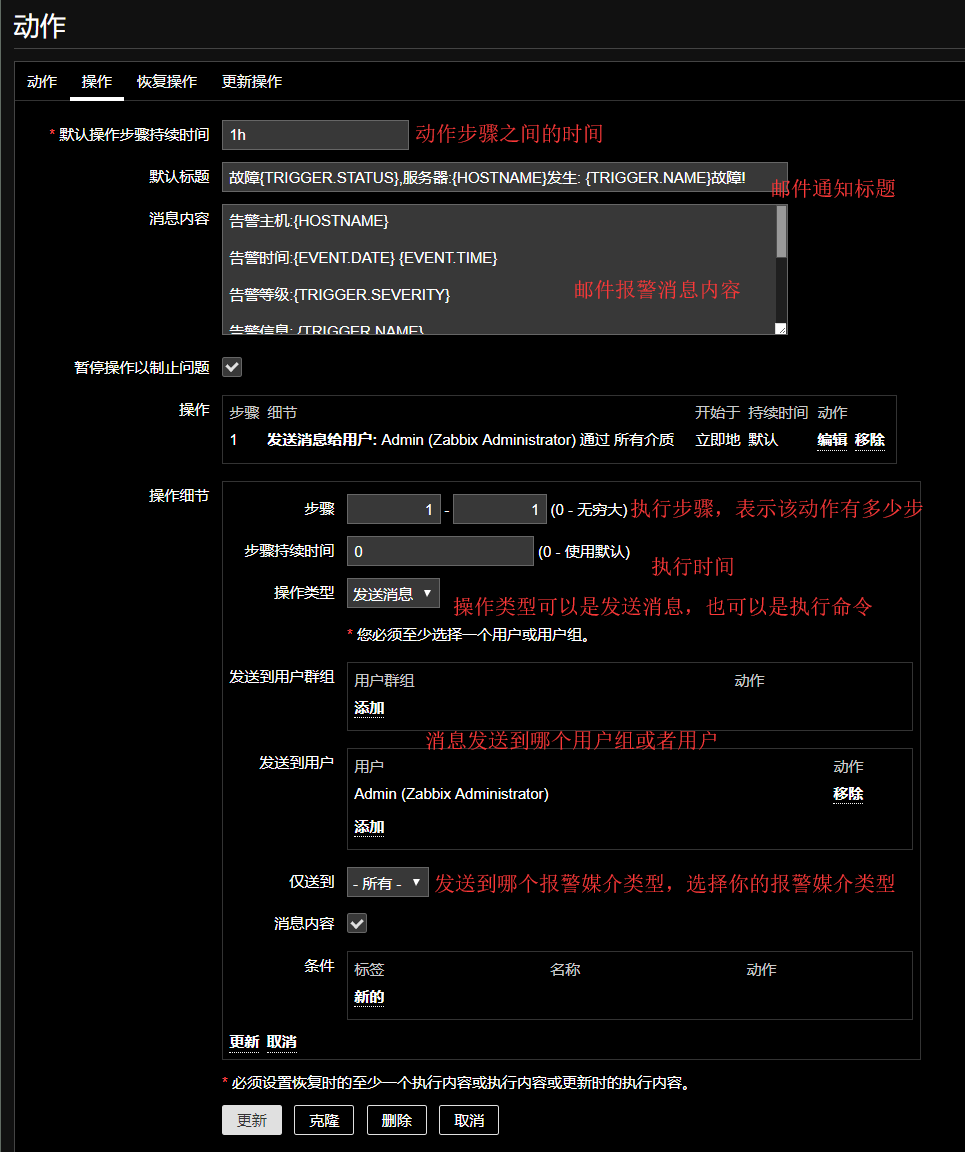
点击恢复操作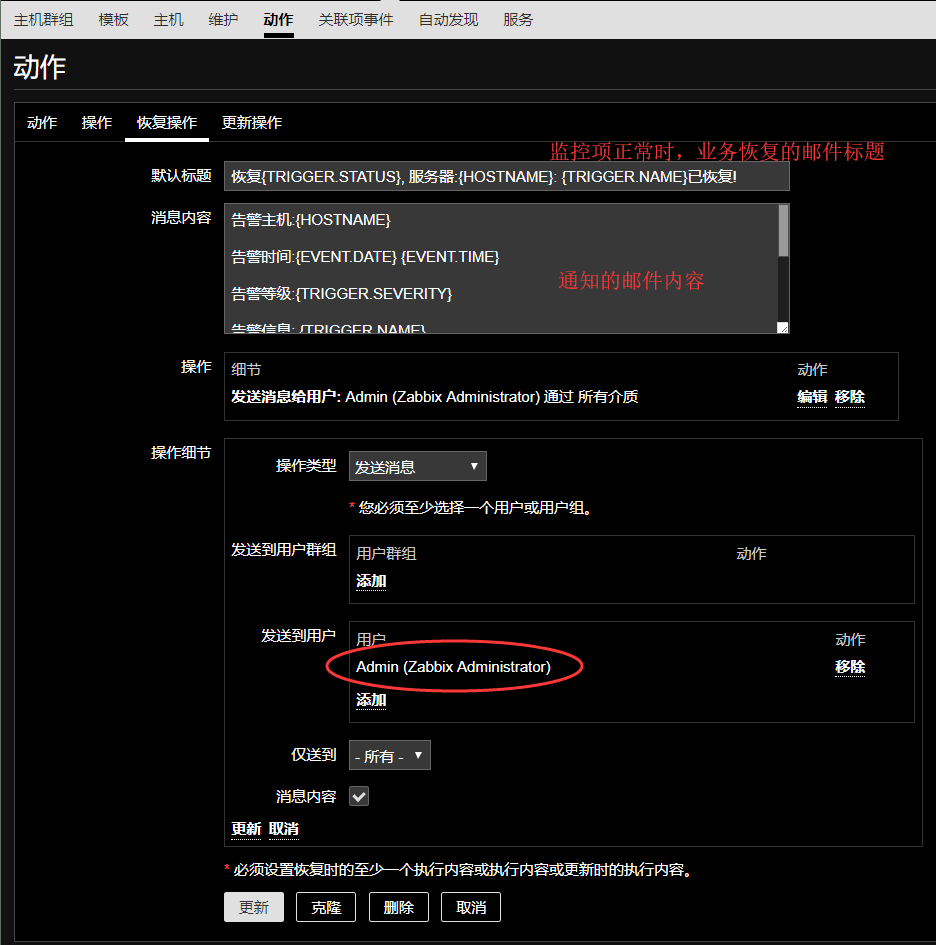
完成以上配置,点击添加即可添加一个对该触发器的动作。
上图报警的宏如下,更多的宏参考官方宏使用 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 故障时
默认标题:故障{TRIGGER.STATUS},服务器:{HOSTNAME}发生: {TRIGGER.NAME}故障!
消息内容:
告警主机:{HOSTNAME}
告警时间:{EVENT.DATE} {EVENT.TIME}
告警等级:{TRIGGER.SEVERITY}
告警信息: {TRIGGER.NAME}
告警项目:{TRIGGER.KEY}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态:{TRIGGER.STATUS}:{ITEM.VALUE}
事件ID:{EVENT.ID}
恢复时
默认标题:恢复{TRIGGER.STATUS}, 服务器:{HOSTNAME}: {TRIGGER.NAME}已恢复!
消息内容:
告警主机:{HOSTNAME}
告警时间:{EVENT.DATE} {EVENT.TIME}
告警等级:{TRIGGER.SEVERITY}
告警信息: {TRIGGER.NAME}
告警项目:{TRIGGER.KEY}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态:{TRIGGER.STATUS}:{ITEM.VALUE}
事件ID:{EVENT.ID}
模拟告警
在此之前我们已经总结了主机、监控项、触发器、事件、动作等相关知识点,但是到目前为止,还没有真正的收到过任何一个zabbix中的警告,那么这次,我们就在之前的基础上,刻意的让磁盘根目录使用率这个监控项达到指定的阈值,看看能否正常的收到报警信息。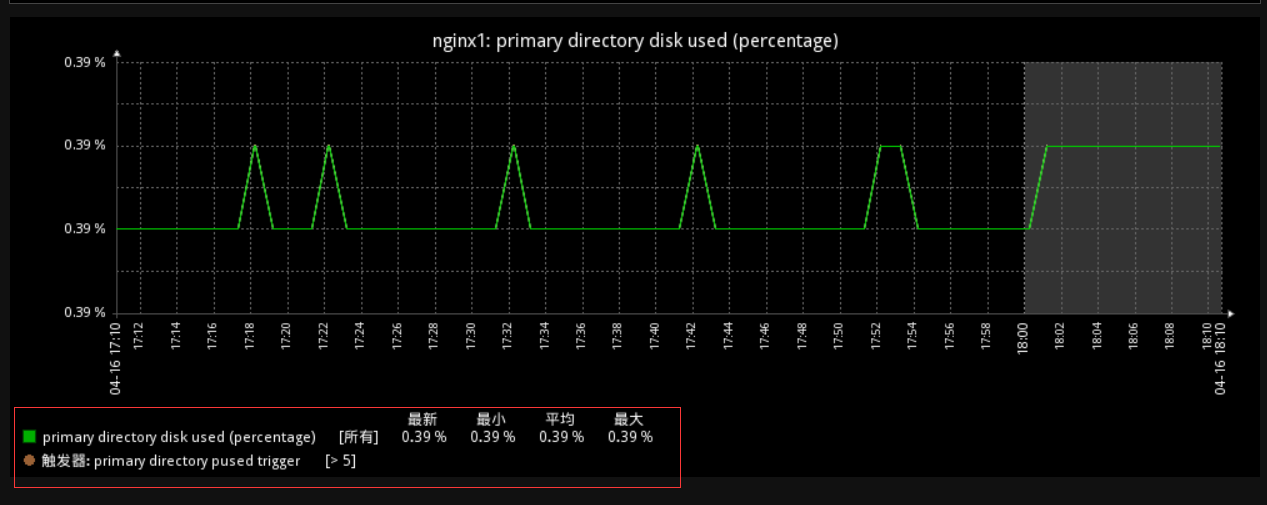
在模拟前,我们先看看之前磁盘根目录使用率是多少,使用率0.39% 阀值5%。好了,现在我们进入到被监控主机的根分区,在根分区中创建一个大文件,提高磁盘使用率。1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@k8s nginx]# dd if=/dev/zero of=/testfile count=20 bs=1G
记录了20+0 的读入
记录了20+0 的写出
21474836480字节(21 GB)已复制,44.8811 秒,478 MB/秒
[root@k8s nginx]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda5 296G 22G 275G 8% /
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 18M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/sda2 200G 33M 200G 1% /home
/dev/sda1 297M 107M 191M 36% /boot
tmpfs 797M 0 797M 0% /run/user/0
此时我们的根分区使用率已经达到了8%,超过了触发器设置的阀值5%,我们看看下图,(这里显示的是7.16%和df -h命令8%差一点点是由于linux只显示整数,小数点增1位)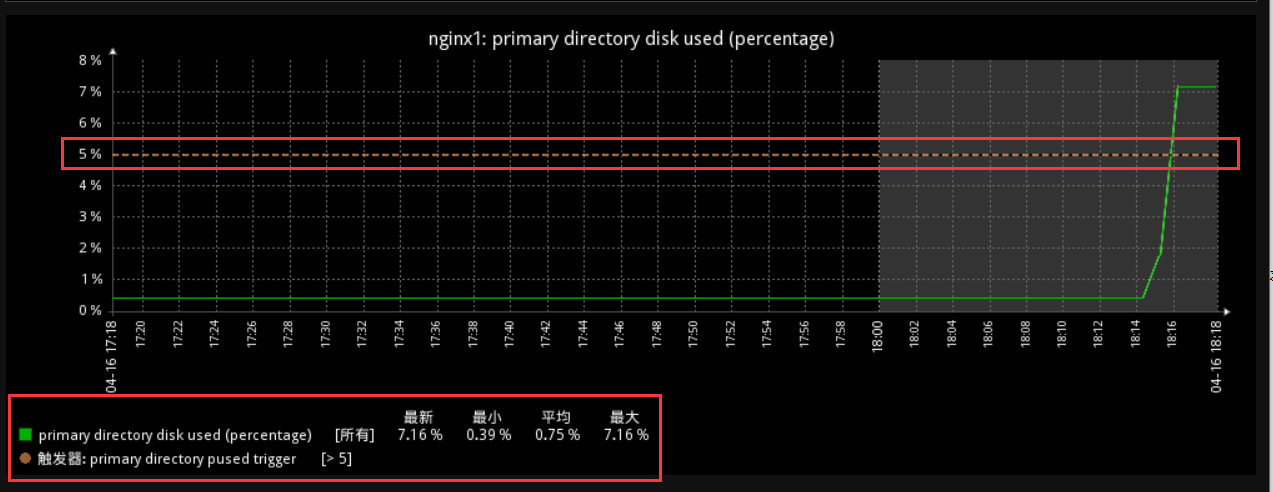
我们配置的是1分钟检测一次,因此我们能很快收到故障邮件通知报警。如下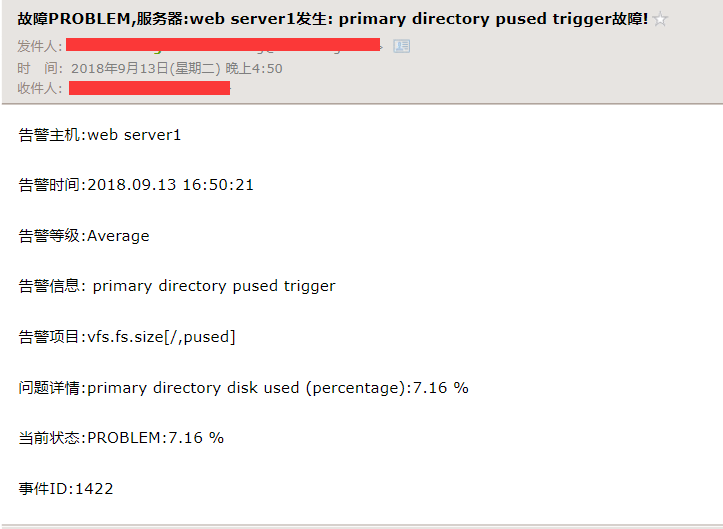
此时我们删掉dd命令生成的testfile文件进行恢复测试。1
2
3
4
5
6
7
8
9
10
11[root@k8s /]# rm -rf testfile
[root@k8s /]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda5 296G 1.2G 295G 1% /
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 18M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/sda2 200G 33M 200G 1% /home
/dev/sda1 297M 107M 191M 36% /boot
tmpfs 797M 0 797M 0% /run/user/0
那么很快我们将收到监控项恢复的邮件通知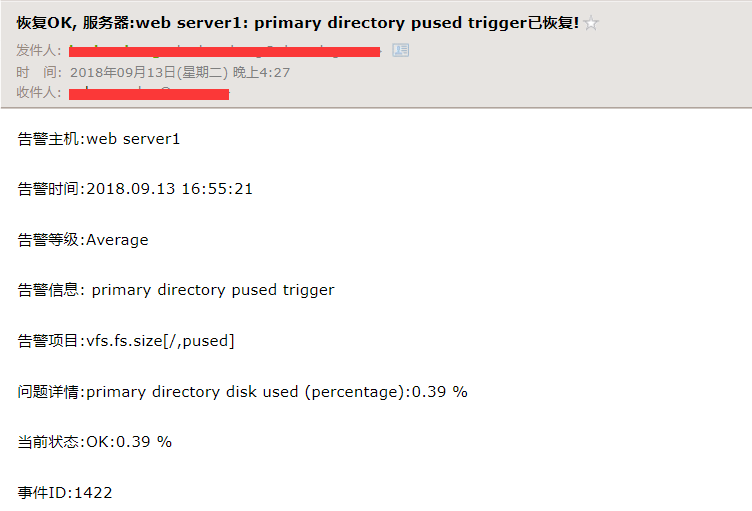
至此,我们已经完成了初步的zabbix使用了。也可以用户监控环境去监控服务了,当然监控项、触发器等还需要根据实际情况去配置。

